Generalization is a machine learning concept that evaluates how a model performs on testing or unseen data. A model could score 99% accuracy on a training model, however if it cannot replicate the accuracy results then the model is useless. Our model could either underfit or overfit in these situations, all to say that they both fail to predict patterns in the data.
Before we explain underfit and overfit, let's understand bias and variance.
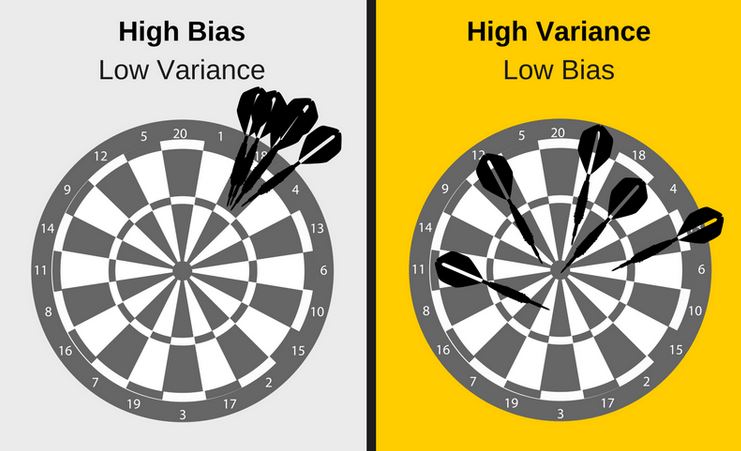
Bias and variance are two predictive models that can differentiate a good model from a not so good model.
According to EliteDataScince, "Bias occurs when an algorithm has less flexibility to learn the true signal from a dataset." A model with high bias will be consistent with it's results however, it would be inaccurate. A good way to remember bias is to think about 'bias towards people'. If you are biased towards someone and would likely make wrong assumptions about them.
On the other hand, EliteDataScience explained variance as "algorithm's sensitivity to specific sets of training data". Such models are usually complex models that try to find patterns using variables that should have no affect. These models are accurate on average however, they are in consistent with their results. For instance, using your name to find the brand of toothpaste would be an example of high variance.

We should also understand that there is a trade off between the two. A high bias model, would be low variance and vice a versa. So as a data scientist you should be looking for a sweet spot.
So you might be wondering where does underfitting and overfitting falls?
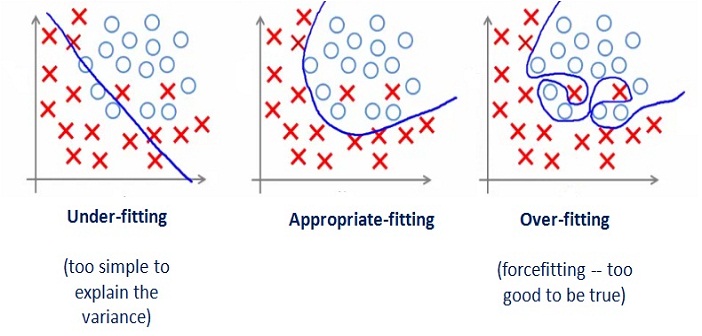
Underfitting
Underfitting occurs when a model does not fit the training data set and therefore cannot be generalized on the new dataset. This could be result of a simple model, that is, there are not enough independent variables to predict the dependent variable. It could also occur when we use linear regression on non-linear dataset. If we have to explain underfitting model in terms of bias/variance, it would be high variance and low bias.
Overfitting
On the other hand, overfitting is a result of a few too many independent variable. Instead of learning the pattern, the model would just memorize the points. It would even consider the noisy points or outliers to find a pattern. Even though the training model would give exceptional predictions, the results would not be replicated on the test dataset. SO if you see 99% accuracy on your training dataset, be suspicious. This complex model would have high variance and low bias.

There are multiple techniques that are used to overcome both underfitting and overfitting however that is a post for another day.